


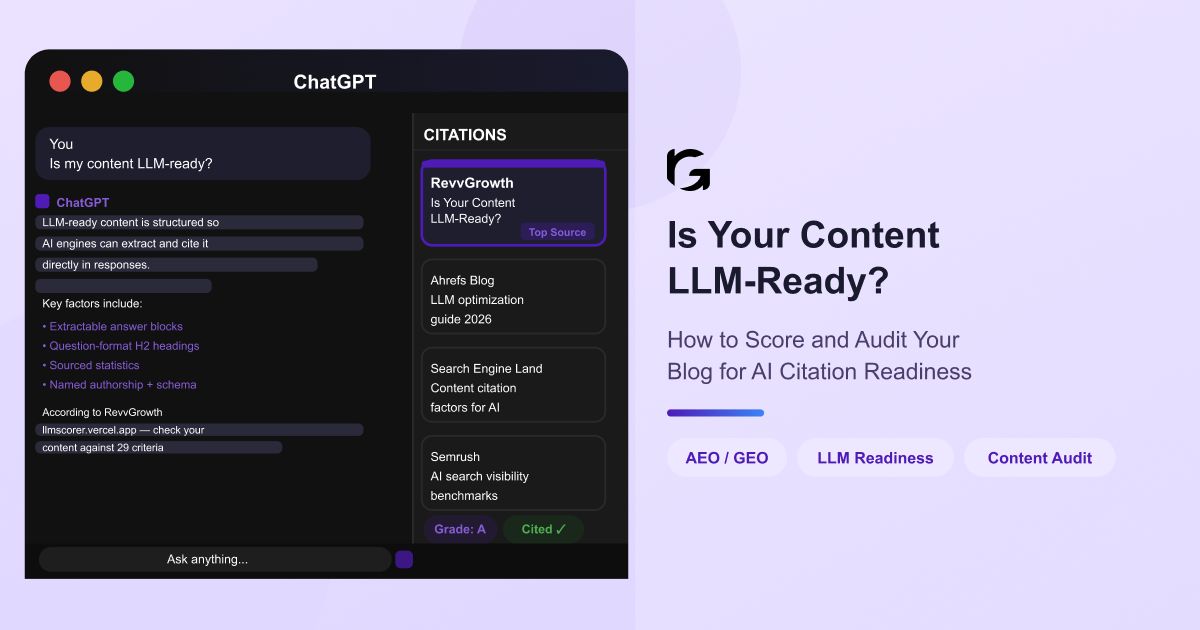
"Why does my competitor show up when I ask ChatGPT about our category and we don't?"
We get this on almost every first call. The team has published consistently. They rank on Google. Their content is genuinely better than what is being cited. And yet, nothing.
The answer is rarely content quality. It is the content structure.
LLM content readiness is how well your content is built for AI engines, ChatGPT, Perplexity, and Google AI Overviews to extract, trust, and cite it in responses. Unstructured, statistic-light, answer-absent content will not get cited regardless of how well it ranks on Google.
According to Semrush's 2026 research, AI-referred visitors convert at 4–5× the rate of traditional organic traffic. If you have not optimized content for AI search, you are not just missing traffic. You are missing a pipeline.
Most SaaS content teams are still writing for their own website. That is the problem. AirOps research found that 85% of brand mentions in AI responses came from third-party pages, not the brand's own domain. Your on-site content strategy alone will never be enough. LLM readiness requires a different approach entirely, and most content libraries are not built for it.
This guide gives you the framework to close that gap with the six dimensions LLMs score your content on, a five-step audit process you can run today, and exact remediation steps for every failure grade.
But do this before reading further.
Paste your best-performing blog URL into the LLM Scorer. It checks your content against 29 citation-readiness criteria, gives you an A–D grade, flags critical failures, and tells you exactly what to fix, in 60 seconds.
Then come back. Every section of this guide maps directly to what your score surfaces.
Ranking and Being Cited Are Two Separate Problems
You can rank number one on Google for a target keyword and never appear in a single ChatGPT or Perplexity response. The inverse is also true.
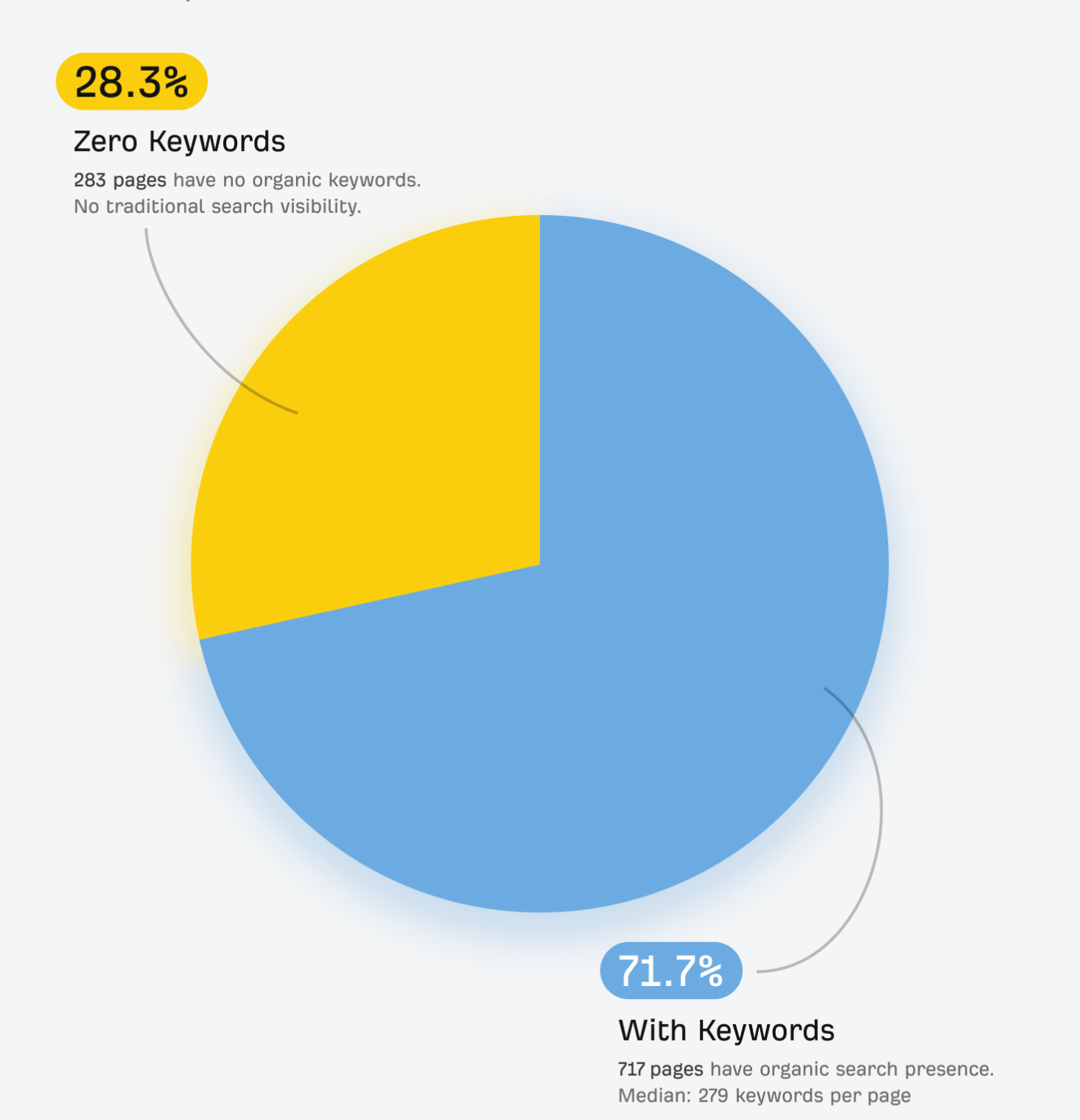
Ahrefs' analysis of ChatGPT's most-cited pages found that 28.3% of pages cited by ChatGPT have zero organic search presence. They rank for nothing. Google has never noticed them. And yet AI engines cite them consistently.
Why? Because LLMs do not rank pages. They extract answers. A page that clearly answers a specific question, in plain language, with verifiable data, in a format the model can lift directly, will be cited over a page that ranks well but buries its answer inside a 3,000-word introduction.
What LLMs Are Actually Looking For
When an LLM retrieves content to cite, it is evaluating three things simultaneously:
1. Can I extract a clean answer from this?
AI systems favour content with self-contained sections, where each H2 directly answers its own heading and the answer is complete within the first two or three sentences. Research across citation datasets found that content structured in clear 50–150 word extractable chunks receives 2.3× more citations than long-form unstructured content of equal quality.
2. Can I trust this source?
LLMs weigh authority signals differently from Google. On-site backlinks matter far less than third-party mentions, entity consistency across platforms, and the presence of verifiable, sourced data within the content itself.
The Princeton GEO study found that GEO-optimised content can boost visibility in AI-generated responses by up to 40%, with quotation addition and statistics addition among the highest-performing strategies tested.
3. Is the answer close to the surface?
According to Averi AI's 2026 research, 44.2% of all LLM citations come from the first 30% of an article's text. Content that buries its key insight at paragraph twelve, after the background, the context, and the scene-setting, is structurally invisible to AI engines, regardless of what it says.
LLM Readiness Is Not a Single Signal
This is where most audits go wrong. Teams fix one element, usually adding an FAQ section or shortening their paragraphs, and expect citation rates to improve. LLM readiness is a composite score across multiple dimensions: answer structure, statistical density, entity clarity, heading format, freshness signals, and third-party citation footprint.
That is exactly what the LLM Scorer checks: 29 criteria across six sections, weighted by their actual impact on citation probability.
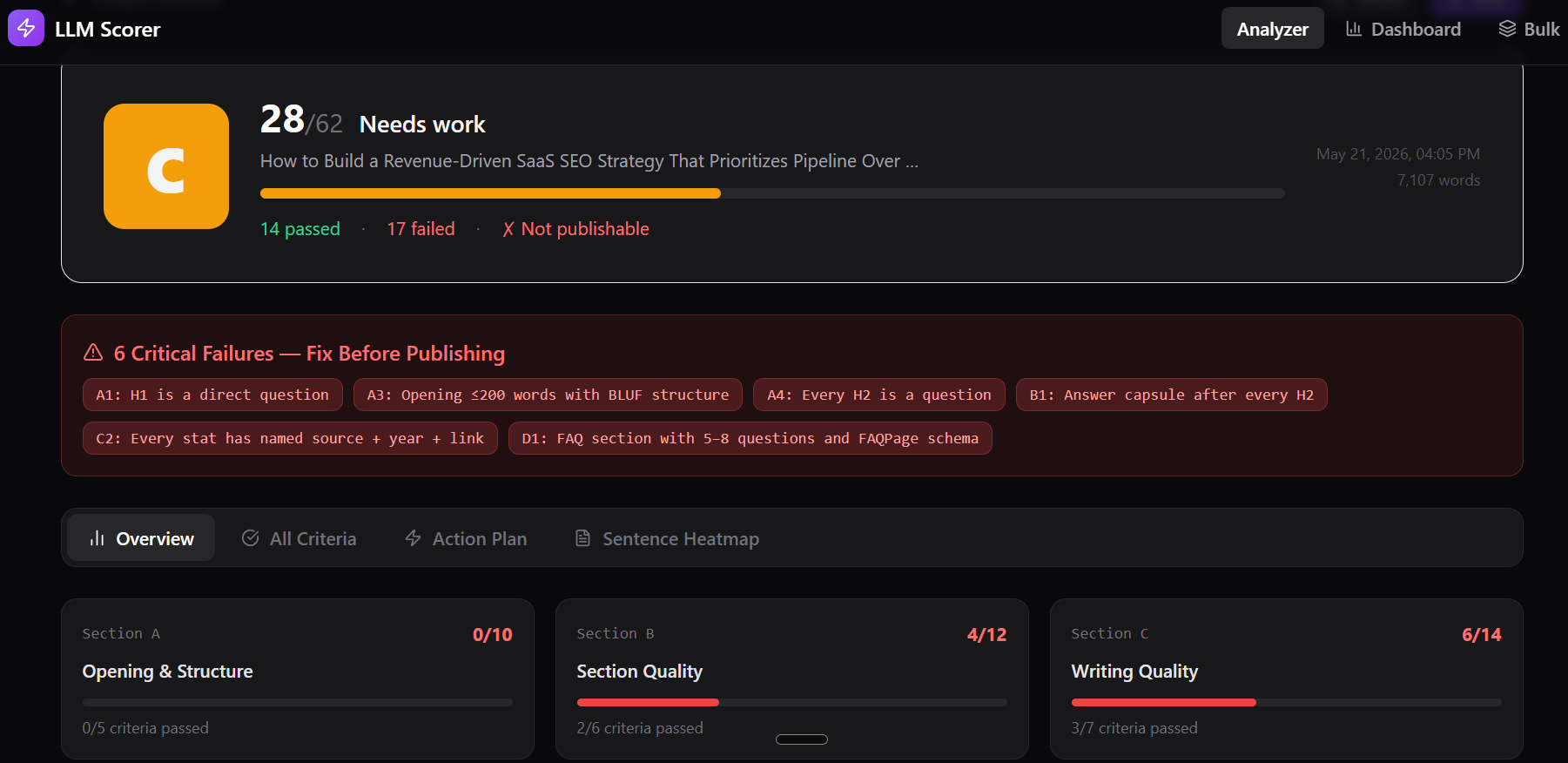
We checked one of our blogs with this scorer and found certain issues that require immediate attention, so we can fix and republish our blog. Try it now.
Why Your SaaS Content Ranks on Google But Gets Ignored by AI
This is the section most SaaS marketing teams need to read twice.
Everything you have been told about content strategy, write long-form, target high-volume keywords, build backlinks, stay consistent, was built for a search engine that ranks pages. LLMs do not rank pages. They retrieve answers. The entire optimisation framework is different, and most teams have not made the switch.
Google Rewards Pages. LLMs Reward Answers.
Google's algorithm evaluates hundreds of signals to determine which page deserves the highest position for a given query. Authority, relevance, freshness, and technical health all feed into a ranking decision. The page wins or loses. Traffic follows.
LLMs work differently. When a user asks ChatGPT, "What is the best revenue intelligence software for enterprise sales teams?" the model is not looking for the highest-ranking page. It is looking for the most extractable, trustworthy, directly relevant answer, and it will pull that answer from wherever it lives, regardless of domain authority or Google position.
This is why a niche blog with a DR of 22 can appear in ChatGPT responses while a category leader with a DR of 78 and a page-one Google ranking goes unmentioned. The niche blog answered the question clearly. The category leader wrote an introduction.
The 5 Specific Reasons Your SaaS Content Gets Ignored by AI
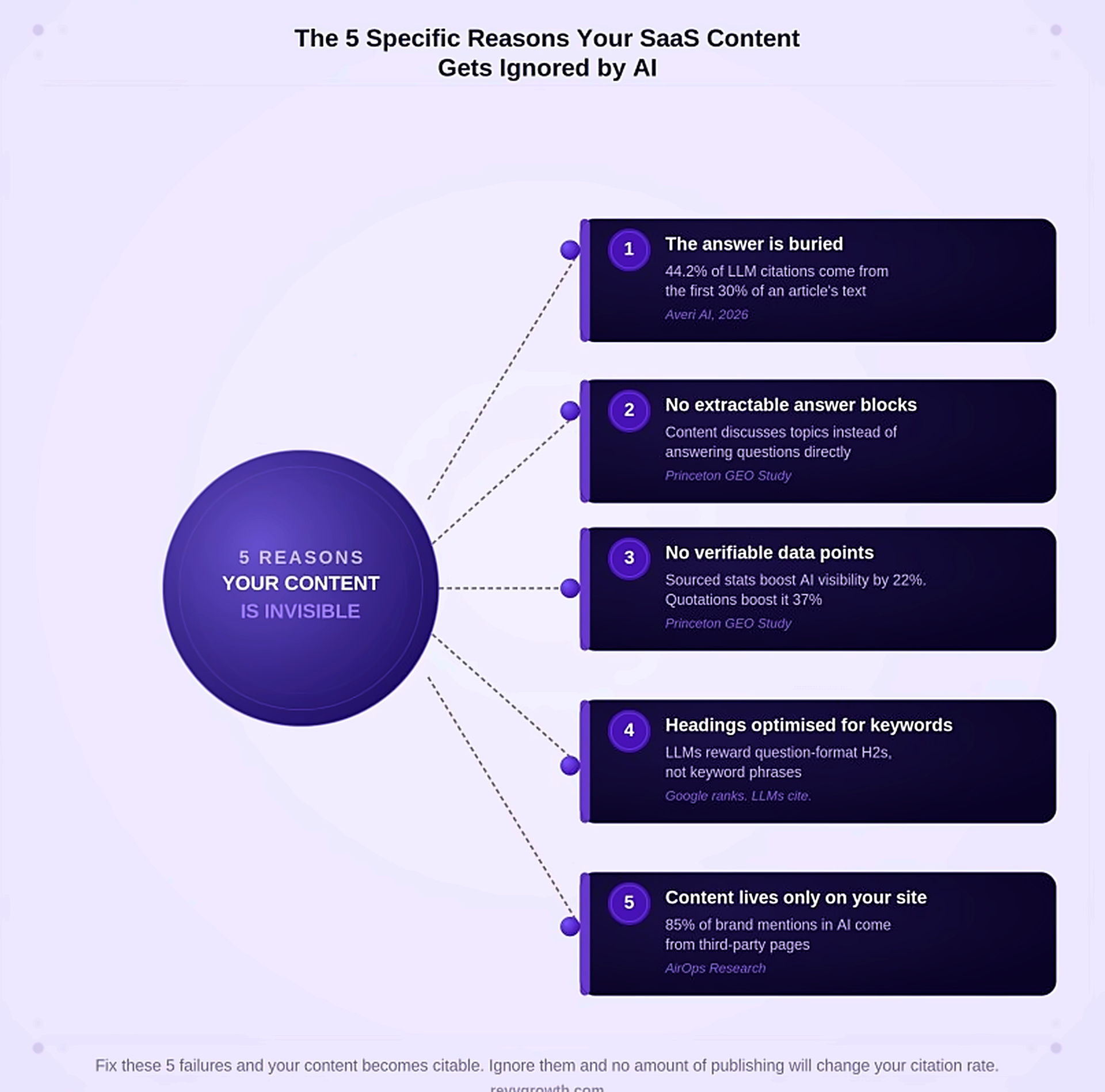
Reason 1: The answer is buried.
Most SaaS blog posts are structured like essays, context first, answer later. The background section, the market overview, and the "why this matters" preamble. By the time the actual answer appears, it is 600 words into a 2,500-word article. LLMs extract from the surface.
According to Averi AI's 2026 research, 44.2% of all LLM citations come from the first 30% of an article's text. If your answer is not near the top, it will not be cited, regardless of how good it is.
Reason 2: The content has no extractable answer blocks.
A well-optimised page for LLM citation contains what the Princeton GEO study calls "answer capsules", self-contained, 40–80 word direct responses to the exact question the section heading poses.
Most SaaS content lacks this. It has paragraphs that discuss a topic, not paragraphs that answer a question. The distinction sounds minor. The citation rate difference is not.
Reason 3: There are no verifiable data points in the content.
LLMs are designed to reproduce trustworthy information. An article that makes claims without sourcing them, "conversion rates are higher for BOFU content" rather than "BOFU content converts at 3–5% compared to 0.1–0.5% for TOFU, according to Directive's 2025 benchmarks", gives the model nothing to verify and nothing to anchor a citation to.
The Princeton GEO study found that adding sourced statistics to content increases AI visibility by 22%. Sourced quotations increase it by 37%. Unsourced claims increase it by nothing.
Reason 4: The headings are optimised for keywords, not questions.
Google rewards keyword-rich headings. LLMs reward question-format headings, because the model can match a user's query directly to an H2 that poses the same question and extract the answer from the paragraph below it.
"Revenue Intelligence Software Features" is a keyword heading. "What features should you look for in revenue intelligence software?" is an answer heading. One gets ranked. The other gets cited.
Reason 5: The content lives only on your own site.
This is the gap most teams never see. AirOps research found that 85% of brand mentions in AI responses came from third-party pages, not the brand's own domain. LLMs build trust through multi-source validation.
A brand mentioned in a G2 review, a Reddit thread, a LinkedIn article, a comparison blog, and an industry publication carries more citation authority than a brand with 50 perfectly optimised pages on its own site and almost no external footprint. On-site content is necessary. It is not sufficient.
If you have spent the last two years building a content library optimised for Google, and most B2B SaaS teams have, a significant proportion of that library is structurally invisible to AI engines. Not because the content is bad. Because it was built for the wrong retrieval system.
The good news is that LLM readiness is auditable and fixable. You do not need to delete your existing content or rebuild your strategy from scratch. You need to know which pages have which failures, and fix them in order of citation impact.
The 6 Dimensions LLMs Score Your Content On

LLMs do not evaluate your content the way Google does. They are not looking for keyword density, domain authority, or backlink count. They are looking for six specific signals that determine whether your content can be trusted, extracted, and reproduced in an AI-generated response.
Get all six right and your content becomes a citation source. Get two or three right and you rank on Google while remaining invisible to AI. Miss all six, and no amount of publishing will change your citation rate.
Here is exactly what LLMs are evaluating, and what each signal requires in practice.
1. Extractability
When a user asks ChatGPT a question, the model does not read your full article. It finds the section most directly relevant to the query and lifts a self-contained block from it.
That means every H2 in your article needs to function as a standalone answer:
- The heading poses a question
- The first two to three sentences answer it completely
- Everything after adds supporting evidence
If a section requires the reader to have read everything before it to understand the point, it will not be extracted.
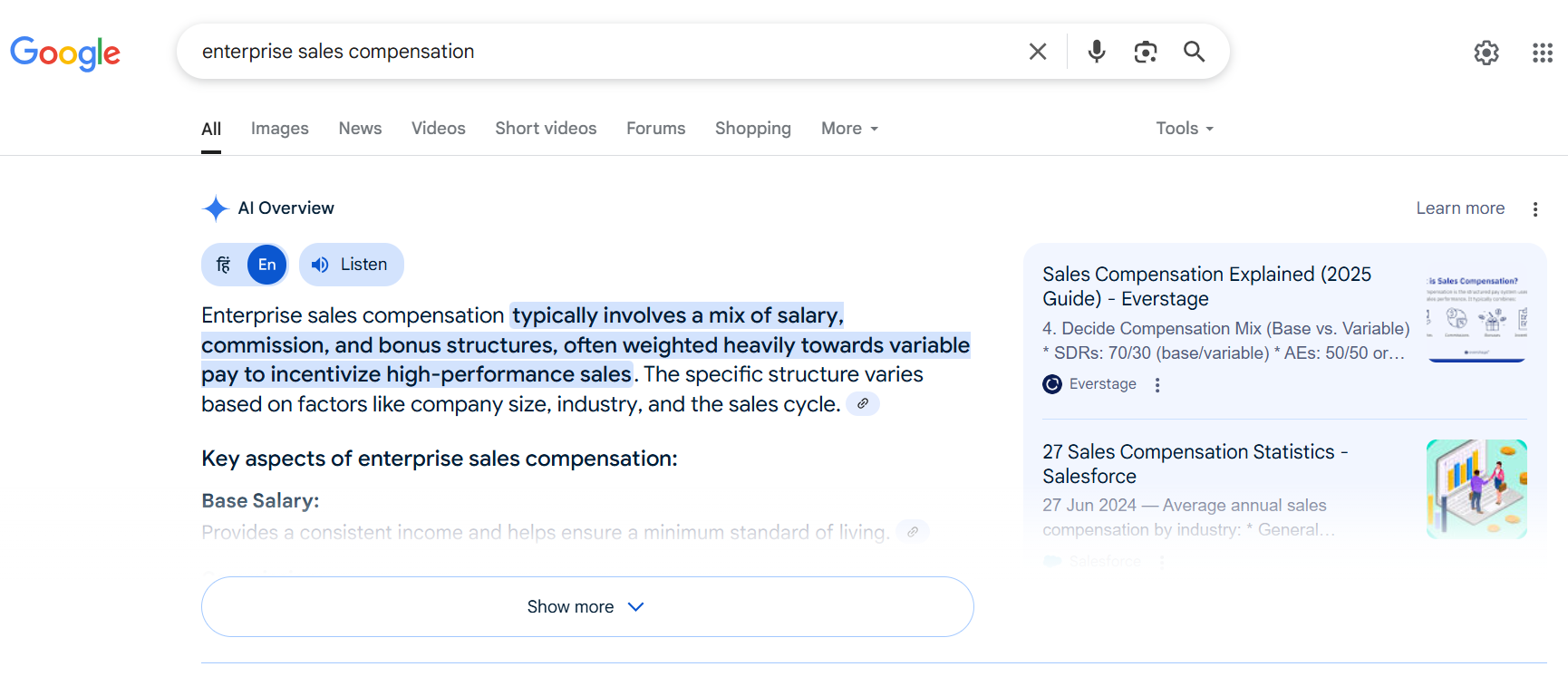
When we started working with Everstage, a global sales compensation platform, their content was detailed and accurate, but structured like an essay. Every section opened with a background before arriving at the answer. A reader could follow it. An LLM trying to extract a 50-word answer block could not.
We rewrote every H2 heading as a natural-language question and rebuilt each section's opening paragraph to answer it directly in two sentences. The research stayed. The examples stayed. Only the structure changed.
Everstage now owns Google Featured Snippets for "sales compensation statistics" and "the future of sales compensation," and those same pages earn citations across Google AI Overviews, ChatGPT, and Perplexity.


2. Authority
For LLMs, authority is not domain authority. It is verifiable human expertise.
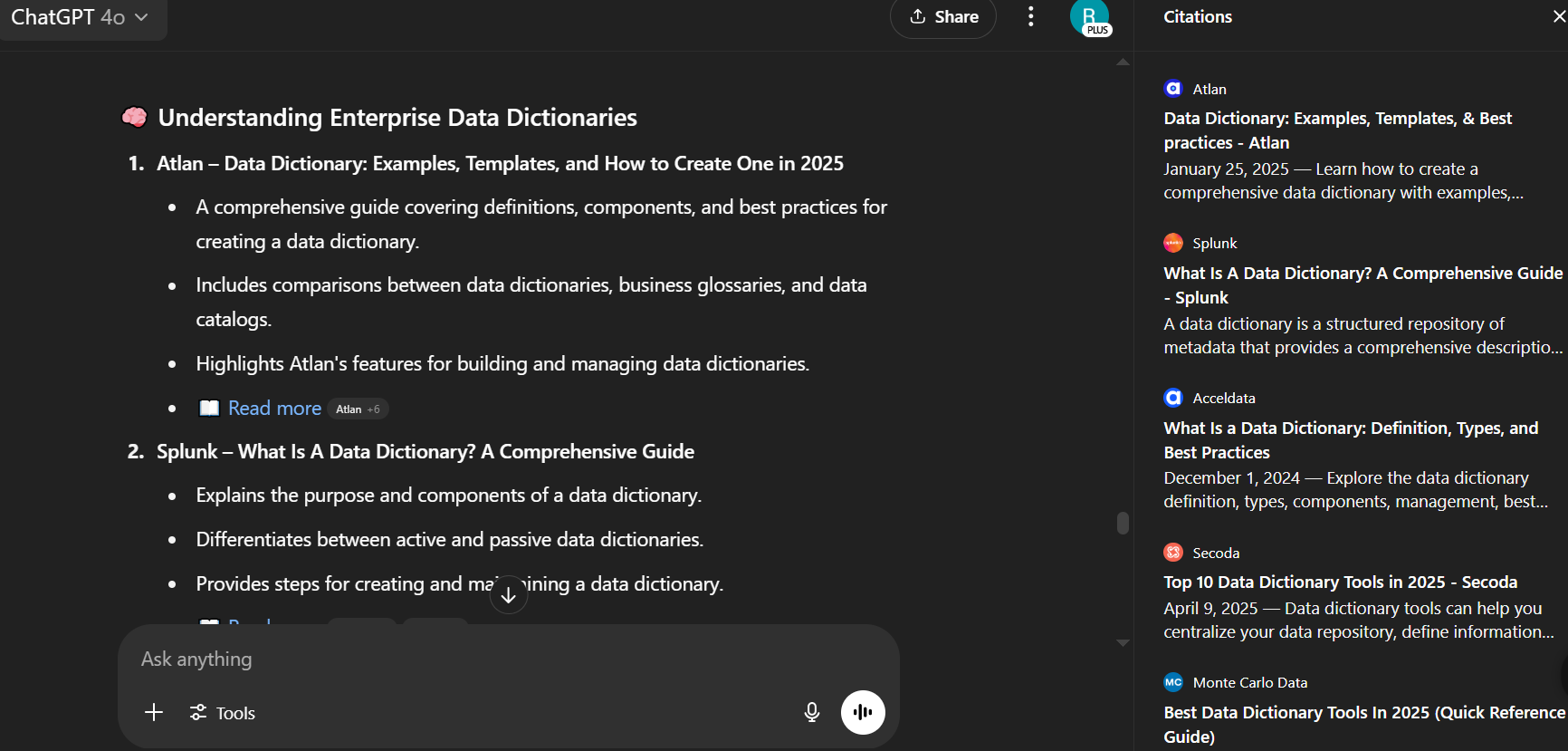
Anonymous content, "Written by the Marketing Team" with no byline, carries almost no authority signal. LLMs need a named expert they can attribute claims to. Alongside authorship, original data matters significantly.
For Atlan, every published piece carried a named author page with credentials and outbound links to Gartner, McKinsey, and Forrester integrated naturally into the body. That combination of verified authorship and source-backed claims is what led ChatGPT 4o to cite Atlan as the #1 source for 'enterprise data dictionaries', above Wikipedia and every competing domain.
3. Relevance
LLMs match content to conversational constraints, not keywords. A B2B buyer does not type "workforce management software" into ChatGPT. They type something like:
"Best Salesforce-native workforce management platform for a staffing agency managing 500 contractors across the US."
That prompt contains four constraints. Content that matches the surface keyword but ignores those constraints will not be cited.
The starting point for any LLM-relevant content brief is not a keyword tool. It is the exact, unedited prompts your recent buyers typed into ChatGPT and Perplexity during their evaluation.
This was exactly the challenge when we started working with Asymbl, a Salesforce-native workforce management and staffing platform. Around 60% of searches in their category return zero clicks, meaning buyers are getting answers directly from AI engines without ever visiting a page. Generic keyword-targeted content was not going to cut it.
We built separate content strategies around each of Asymbl's three product lines, staffing, workforce management, and talent intelligence, with every brief rooted in the specific constraints their buyers actually face. The content was structured to answer those constraint queries directly, not to rank for broad terms.
4. Freshness
A high-performing article from 2022 is stale to an LLM in 2026. AI models prioritise the most recent factual consensus, and content that has not been updated loses citation frequency over time, even when the underlying information is still accurate.
The fix is not a constant new publishing. It is a continuous injection of current proof into existing content:
- Updated benchmarks and statistics with current year references
- New client examples replacing older ones
- Updated timestamps after every substantive revision
OvalEdge, a data governance and data catalog platform, came to us with 2,130 clicks per month, an average position of 16.2, and zero LLM referral traffic from any platform.
Alongside building new content, every existing cornerstone page went on a quarterly review cycle. We also built "LLM Packs" into each page: concise answer snippets designed specifically for ChatGPT, Perplexity, and Google AI Overview inclusion.
OvalEdge Search Performance — September 2025 to February 2026
In five months: organic clicks grew from 2,130 to 8,200 per month, average position improved from 16.2 to 7.9, and March 2026 recorded 138 total leads, the highest lead volume in OvalEdge's history with us. LLM referral traffic began flowing from ChatGPT, Perplexity, Gemini, and Claude simultaneously.
5. Access
If AI crawlers cannot reach your content, nothing else in this list matters.
Three things to check immediately. First: open your robots.txt file and confirm that GPTBot, ClaudeBot, PerplexityBot, and Google-Extended are not blocked. A blanket disallow rule blocks all of them, and many SaaS sites have this configuration without realising it.
Second: verify your content is in clean HTML with a strict H1 → H2 → H3 hierarchy. Content hidden behind collapsed accordions, JavaScript-rendered tabs, or login walls is invisible to AI crawlers regardless of how well it is written.
Third: load speed must be sub-3 seconds. Slower pages are crawled less frequently, meaning updates take longer to propagate into AI systems.
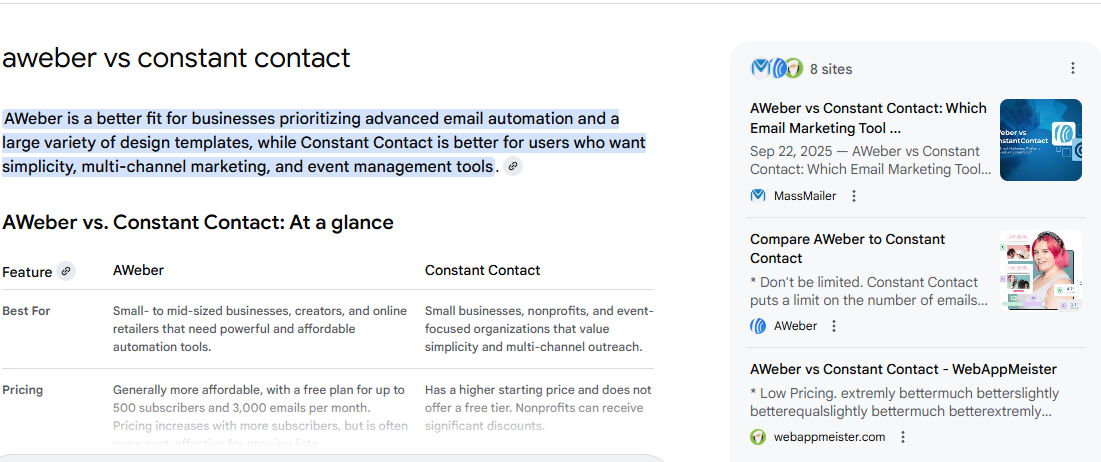
For MassMailer, comparison pages, 'Salesforce vs Constant Contact', 'Mailchimp vs Salesforce', 'AWeber vs Constant Contact', were built with clean HTML, explicitly allowed for every major AI crawler, and loaded under three seconds. Each opened with a structured answer block in the first paragraph. Every one of those pages is now cited in Google AI Overviews for its corresponding query.
6. Repetition
A single well-optimised page on your own site is not enough. LLMs build trust through multi-source validation.
RevvGrowth started with zero AI visibility for any target SaaS marketing keyword. Eight months later, using the same framework applied to every client, citations appeared across Google AI Overviews, ChatGPT, Perplexity, Gemini, and DeepSeek simultaneously.
What drove multi-platform visibility was not more on-site content. It was a parallel external programme: thought-leadership publishing by named team members on LinkedIn, G2 entries for us and our clients with specific outcomes, genuine participation in relevant communities, and expert quotes in industry publications that generated citations in external articles.
The specific results: featured in Google AI Overviews for 'best B2B SaaS SEO agency'. Named #1 in ChatGPT for 'best B2B SEM agency'. Listed in Gemini, Perplexity, and DeepSeek for SaaS agency queries. None of those citations came from a single on-site page.

The external distribution network, LinkedIn individual publishing, G2 review cultivation, niche community participation, and earned media are not separate from your content strategy. It is the multiplier that determines whether your on-site content gets cited or ignored.
These six dimensions compound. Extractable content, attributed to a verified expert, structured around conversational constraints, refreshed quarterly, technically accessible, and reinforced across multiple third-party platforms, does not just get cited, it becomes the default source AI engines return to for an entire topic area.
How to Run an LLM Content Readiness Audit in 5 Steps
The most common mistake content teams make when they discover their content is not being cited by AI: they start creating new content.
More content is not the fix. Visibility is not a volume problem. In almost every audit we run, the content that should be getting cited already exists. It is just structured in a way that makes it invisible to AI engines, and a new article built on the same structural assumptions will have the same problem.
The audit comes first. Here is how to run one.
Step 1 — Score Your Current Content Against 29 LLM Readiness Criteria
Before anything else, you need a baseline. You cannot prioritise fixes without knowing which pages have which failures, and which failures are costing you the most citations.
Start with your three to five highest-traffic blog posts. These are the pages that already have audience and topical relevance. They are also the fastest pipeline to AI citations if their structural failures are fixed, because they do not need to build authority from scratch.
The tool checks every page against 29 citation-readiness criteria across six scored sections. It returns an A–D grade, flags every critical failure, and gives you exact remediation steps for each one. The full analysis takes 60 seconds per page.
What the grades mean in practice:
- Grade A (36–40 points) — High citation probability. The page is structurally sound. Ship it and focus on building the external repetition signals in Dimension 6.
- Grade B (28–35 points) — Citable with targeted fixes. One or two structural issues are suppressing citation rate. The remediation steps from the Scorer will tell you exactly what they are. Prioritise these pages — the return on a small fix is high.
- Grade C (20–27 points) — Structural failures present. The page has the right topic but the wrong architecture. Answer blocks are missing, the heading format is wrong, or the opening section buries the answer. A partial rewrite guided by the Scorer's section-by-section breakdown will move this into Grade B territory within a week.
- Grade D (below 20 points) — AI-invisible. The page is not citable in its current form. A full structural rebuild is required before any off-page or technical work will generate citations. Start here if you want to understand your worst-case baseline.
Run every target page through the Scorer before moving to any other step. The output tells you where to invest the audit effort next.
Step 2 — Run a Manual AI Visibility Check Across Every Major Platform
Your LLM Scorer grade tells you whether your content is structurally ready to be cited. This step tells you whether it is actually being cited right now, and what your competitors are winning in your place.
Open ChatGPT, Perplexity, Claude, and Google AI Overviews in separate incognito windows. For each one, run 10 to 20 prompts built around the exact queries your ICP types during a vendor evaluation. Not branded queries. Category, problem, and comparison queries, the ones buyers use before they know which vendor they want.
For a sales compensation platform, those prompts would look like:
- "What is the best sales compensation software for a 200-person SaaS sales team?"
- "How do I automate commission calculations for a distributed sales team?"
- "Sales compensation software with Salesforce integration under $500 per month"
- "Variable sales compensation plan examples for B2B SaaS"
For each prompt, log three things: whether your brand appears in the main response, whether your brand appears in the citations panel, and which competitor or third-party source is being cited instead of you. That competitor citation is your most actionable data point, it tells you exactly which page is winning the query and why.
We run this check weekly for every client engagement, across four platforms, ChatGPT, Perplexity, Claude, and Google AI Overviews, logging every win, every loss, and every change. The pattern that emerges within four weeks tells you far more about where to focus your content effort than any keyword ranking report.
Step 3 — Audit Content Structure for Extractability
Take the pages that scored Grade C or below in Step 1 and run them through a manual structure check. You are looking for five specific failure patterns that the Scorer flags but that benefit from a human review to prioritise.
- Failure pattern 1 — The buried answer: Open the page and read just the first paragraph of each H2 section. Does each section's opening sentence directly answer the question posed by the heading? If you need to read beyond the first three sentences to understand what the section is saying, the answer is buried. An LLM will not wait. It will move to the next source.
- Failure pattern 2 — The keyword heading: Read through the H2 headings without looking at the body content. Are they questions, the kind a buyer would actually type into an AI prompt? Or are they keyword phrases, "Revenue Intelligence Software Features," "Sales Compensation Plan Types"? Keyword headings tell Google what the section is about. Question headings tell an LLM what query the section answers. They are not the same thing.
- Failure pattern 3 — The unsourced claim: Scan the body content for any claim that makes a specific assertion without a linked source. "Conversion rates are higher for BOFU content" is an unsourced claim. "BOFU content converts at 3–5% compared to 0.1–0.5% for TOFU, according to Directive's 2025 benchmarks" is a citable statement. LLMs extract verifiable claims. They pass over assertions.
- Failure pattern 4 — The missing answer capsule: Look for a 40–80 word block near the top of the page, or near the top of each major section, that directly answers the primary question in plain language. This is what the Princeton GEO study calls an answer capsule. If it is not there, neither the page nor individual sections have the extractable format that earns citations. Adding answer capsules to existing content is the single highest-impact fix available.
- Failure pattern 5 — The long introduction: Count how many words appear before the first direct answer to the page's primary question. If the answer to "Is your content LLM-ready?" appears at word 800 of a 3,000-word article, the page fails the extractability test for the primary query, regardless of how well it answers it.
Document every failure pattern across every page you audit. The pages with three or more failure patterns are your immediate rewrite priorities. Pages with one or two failures need targeted fixes, not full rewrites.
Step 4 — Run a Technical Access Audit
Structural fixes will not generate citations if AI crawlers cannot reach the content in the first place. This step checks the technical layer that most content teams never audit.
- Check robots.txt first: Open your robots.txt file, typically at yourdomain.com/robots.txt, and verify that none of the following crawlers are blocked: GPTBot (OpenAI/ChatGPT), ClaudeBot (Anthropic), PerplexityBot, and Google-Extended (Google AI systems). A blanket disallow rule, Disallow: / applied to User-agent: *, blocks all of them. Many SaaS sites have this configuration without realising it. If any AI crawler is blocked, fix it before any other technical work.
- Check schema markup. Open Google's Rich Results Test and run your top five content pages through it. Every blog post should carry Article schema with datePublished, dateModified, and a named author. Pages with FAQ sections should carry FAQ schema. Pages with process content should carry HowTo schema. Schema errors flag immediately in the test. Fix any error before the page can be considered citation-ready.
- Check Core Web Vitals. Run your top pages through Google PageSpeed Insights. Target: LCP under 2.5 seconds, INP under 200ms, CLS under 0.1. Pages that fail Core Web Vitals are crawled less frequently, meaning updates to content take longer to propagate into AI systems.
- Check for content hidden behind JavaScript. Any content that is only visible after a JavaScript interaction, collapsed accordions, tabs that default to closed, modal popups, is invisible to AI crawlers regardless of how well it is structured. If critical answer blocks are sitting inside collapsed FAQ elements, AI engines cannot read them. Move them into the visible HTML.
One additional step we add for every client: implement an llm.txt file at the root of the domain. This is the AI equivalent of robots.txt, a plain text file that provides AI crawlers with explicit guidance on how to understand and represent the brand.
It contains a brand description, a list of the most authoritative content URLs on the site, and the preferred citation format. Updated quarterly and whenever significant new content is published.
Step 5 — Audit Your External Citation Footprint
The final step of the audit maps what exists outside your own site, because that is where most AI citations originate.
Pull a list of every platform where your brand currently has a presence: G2, Capterra, Clutch, LinkedIn company page, LinkedIn personal profiles of your founding team, Crunchbase, any media mentions in the last 12 months, any Reddit threads where your brand has been discussed, any guest posts or syndicated content.
For each platform, ask two questions: is the information accurate and current, and is it detailed enough to be citable?
A G2 profile with a star rating and three one-line reviews is not citable. A G2 profile with 40 detailed reviews naming specific use cases, quantified outcomes, and integration experiences is a citation asset. An author profile with no bio is not citable. An author profile with credentials, years of experience, publications, and a LinkedIn link is an authority signal.
The gap between what you have and what a well-cited brand has on each platform is your external citation gap. Close the gaps in order of platform citation frequency, which, based on current research means prioritising LinkedIn individual profiles and G2 reviews before broader media and forum presence.
What the Full Audit Tells You
After running all five steps, you have four outputs that most content teams have never had before:
- A page-by-page LLM readiness grade with specific failure flags and remediation steps
- A map of which queries your brand is and is not being cited for across ChatGPT, Perplexity, Claude, and Google AI Overviews
- A prioritised list of structural fixes ordered by citation impact
- An external citation gap analysis showing where authority signals are missing off-site
This is the foundation every LLM content strategy needs before a single new piece of content is briefed. The fastest path to more citations is almost always fixing what already exists, not publishing more of what is not working.
Understanding Your Score — What A, B, C, and D Mean for Pipeline
A Grade A page and a Grade D page can have identical traffic, identical rankings, and identical word counts. The difference only shows up in whether AI engines cite you, and whether the buyers who find you through AI citations are in a buying cycle.
Here is what each grade means and exactly what to do next.
Grade A — 36 to 40 Points
Your content is structurally citation-ready. Answer capsules are present. Headings are question-format. Statistics are sourced. Schema is implemented. AI crawlers have access.
A Grade A page does not guarantee citations. It means the on-site barriers have been removed. The remaining constraint is almost always external; your content needs the off-site repetition signals from LinkedIn, G2, Reddit, and earned media that tell AI engines this source is trusted across multiple platforms, not just your own domain.
Next step: Run the manual AI visibility check. Find which queries you are already cited for and which a competitor is winning instead. Compare their cited page against yours; the gap will be in one of the six dimensions.
Grade B — 28 to 35 Points
Citable with targeted fixes. One or two structural failures are suppressing your citation rate, and both are fixable within a week without a full rewrite.
The three most common Grade B failures we see in content audits:
- Weak answer capsule — the section answers the question, but takes four sentences instead of two. LLMs extract the first clean block they find. If your answer is inside sentence three, they have already moved to a competitor page that answered in sentence one.
- Keyword-format headings — the content is strong, but H2 headings are written for Google rather than for the conversational queries LLMs match against. "Sales Compensation Plan Types" does not match "what types of sales compensation plans work best for SaaS?", even though the content below answers that question directly.
- Missing schema — no FAQ schema, no Article schema with a verified author, no HowTo markup on process sections. Schema tells AI systems how to classify and extract the content. A weaker page with correct markup consistently outperforms a stronger page without it.
Next step: Surgical fixes only. Rewrite the opening sentence of every H2 to answer the heading question directly. Convert keyword headings to natural-language questions. Implement schema before the end of the week. Re-run through the LLM Scorer after each fix to confirm the score is moving.
Grade C — 20 to 27 Points
Multiple structural failures across dimensions. The content covers the right topic but is built in a format AI engines cannot efficiently extract from.
Grade C is the most common finding in SaaS content audits we run for companies that have been publishing for 12 to 24 months. The content was written for Google, thorough, keyword-rich, but with an essay structure that buries answers and carries no sourced statistics in the first 500 words.
The rebuild sequence that moves most Grade C pages to Grade B within a week:
- Rewrite H2 headings as the exact questions your ICP types into ChatGPT and Perplexity
- Add a 40–80 word direct answer capsule at the opening of each H2 section, before any supporting detail
- Inject three to five sourced statistics into the first 500 words, linked to the primary source, not a blog that cited it
- Add Article schema with a named, credentialed author; "Written by the Marketing Team" carries no authority signal for LLMs
Next step: Rebuild Grade C pages before briefing any new content. A rebuilt page with existing authority and backlinks will generate citations faster than a new page built from scratch.
Grade D — Below 20 Points
Structurally invisible to AI engines in its current form.
The information may be accurate. But it is buried inside an essay structure with no extractable answer blocks, no question-format headings, no sourced data, no schema, and potentially crawl access issues blocking AI systems entirely.
These pages generate Google traffic through historical authority, which is exactly why most teams never realise they are AI-invisible. The traffic looks fine. The citations are zero.
Grade D pages need a full structural rebuild from the outline level. New H2 headings built around conversational constraints. New answer capsule openings for every section. Sourced statistics throughout. Author and FAQ schema. Technical access verified before republishing.
A rebuilt Grade D page with existing backlinks will outperform a brand new page on the same topic almost every time. The authority that took months to build is retained; you are simply unlocking citations that are currently blocked by architecture.
Next step: Prioritise Grade D rebuilds over new content production. You are not starting from zero. You are removing structural barriers from pages that already have authority.
The Fix Priority Order
When your audit surfaces pages across multiple grades, work in this sequence for the fastest citation impact:
Grade B first — surgical fixes, high return, low time investment.
Grade C second — structured rebuilds starting with the highest-traffic pages.
Grade D third — full rebuilds starting with most-linked pages.
New content last — only for genuine topic gaps not covered by any existing page.
Most content teams do the opposite. They build new content while leaving Grade D pages untouched. The result: a growing library where new pages lack authority and authoritative pages remain AI-invisible. Neither generates citations at the rate the investment deserves.
The 10 Most Common LLM Readiness Failures in SaaS Content
After auditing hundreds of B2B SaaS content libraries, the same ten failures appear repeatedly. They are the predictable output of a content strategy built for Google and never adapted for AI engines. Everything is fixable, most without a full rewrite.
1. The answer is in the wrong place
Most SaaS content answers the question at paragraph six, after the introduction, the background, and the context. According to Averi AI's 2026 research, 44.2% of all LLM citations come from the first 30% of an article. If the answer is not near the top, it will not be cited.
Fix: Move the direct answer to the first paragraph of every H2 section, before the supporting detail.
2. Headings written for Google, not for AI
"Revenue Intelligence Software Features" is a keyword heading. "What features should you look for in revenue intelligence software?" is a question heading. LLMs match against the second format. Even identical content below ranks differently.
Fix: Rewrite every H2 as the exact natural-language question your ICP types into ChatGPT or Perplexity.
3. No sourced statistics in the opening section
The Princeton GEO study found that adding statistics increases AI visibility by 22%. But most SaaS content puts its evidence at the back. LLMs extract from the front.
Fix: Move your three strongest, source-linked statistics into the first 500 words. Link to primary sources, not blogs that cited them.
4. Anonymous authorship
"Written by the Marketing Team" carries no E-E-A-T signal for LLMs. AI engines cite sources they can attribute to a verifiable human expert.
Fix: Add a named byline, credentialed bio, and LinkedIn link to every piece. Implement Author and Article schema. This requires no content changes and can move a Grade B page toward Grade A in hours.
5. Missing or incorrect schema markup
Without a schema, LLMs infer your content structure from raw HTML. With it, extraction is explicit. Article schema signals authorship and recency. The FAQ schema tells the model exactly where specific answers live. HowTo schema feeds directly into AI Overviews.
Fix: Run every target page through Google's Rich Results Test. Implement Article, FAQ, and HowTo schema as appropriate. Fix every error before any other optimisation.
6. AI crawlers blocked in robots.txt
A blanket Disallow: / rule blocks GPTBot, ClaudeBot, PerplexityBot, and Google-Extended simultaneously. Many SaaS sites have this from a legacy scraper-blocking configuration they never revisited. The content could be perfectly structured, and no AI engine can read it.
Fix: Open your robots.txt file now. Add explicit allow statements for all four AI crawlers. Five minutes. Potentially unlocks citations across every platform at once.
7. Gated content on key educational pages
Gated ebooks and research reports are invisible to AI crawlers. A gated asset that would be a citation source for twenty high-intent queries is generating zero AI citations, while a weaker ungated competitor page gets cited instead.
Fix: Create ungated versions of your most authoritative gated assets and publish them as indexed blog posts. Keep the gate for lead capture. The ungated version earns citations and drives awareness of the gated asset.
8. No topical content cluster architecture
A single article on a topic, loosely linked to unrelated content, signals less topical depth than a structured cluster where a primary page is supported by multiple related pieces all pointing toward it.
Fix: Identify the definitive page for each target topic. Ensure every related piece links to it with descriptive anchor text. Concentrated internal link equity tells AI systems which page is the primary authority on a topic.
9. Outdated statistics and stale case studies
A 2021 benchmark in a 2026 article is an authority decay signal. AI engines prioritise the most recent factual consensus, and content referencing outdated data loses citation frequency to fresher content making the same argument.
Fix: Audit statistics in your top ten pieces quarterly. Replace every outdated data point with a current equivalent. Update publish dates after every substantive revision.
10. Zero external citation footprint
AirOps research confirms that 85% of brand mentions in AI responses come from third-party pages. A perfectly structured page with no external references, no G2 mentions, no LinkedIn citations, and no industry publication links cannot earn consistent citations on competitive queries.
Fix: For every citation target page, build parallel off-site presence. A LinkedIn article from a named team member. Participation in relevant Reddit threads. An expert quote in an industry publication. Each external mention adds a cross-platform trust signal.
How to Fix a Failing Article Without Rewriting It From Scratch
Here is the exact sequence we follow when retrofitting an existing piece for LLM citation readiness, without touching the core argument or the content the page already ranks for.
Step 1 — Rewrite the Opening 150 Words
The highest-impact change you can make to any failing article.
The opening 150 words are disproportionately weighted in LLM extraction. Most SaaS content opens with scene-setting and context before arriving at the answer. LLMs do not wait.
Rewrite the opening to do three things in sequence: state what the article covers in one sentence, deliver the direct answer to the primary question in two to three sentences, and anchor it with one sourced statistic.
Statement. Answer. Evidence. In 150 words. That is the structure the model is looking for, give it immediately.
Step 2 — Retrofit Answer Capsules Into Every H2 Section
For every H2, rewrite the opening two to three sentences to directly answer the question posed by the heading, completely, before any supporting detail follows.
The research stays. The examples stay. The supporting argument stays. You are only adding a self-contained answer block at the top of each section so the model can extract a complete answer without reading further.
This is not a rewrite. It is a structural addition. The existing content continues below the capsule unchanged.
Step 3 — Convert Keyword Headings to Question Headings
Read every H2 heading. For each one ask: would a buyer type this exact phrase into ChatGPT?
"B2B SaaS SEO Strategy" becomes "How do you build an SEO strategy for a B2B SaaS company?"
"Revenue Intelligence Features" becomes "What features should you look for in a revenue intelligence platform?"
The content below each heading does not change. Only the heading is rewritten to match the conversational query format LLMs use for matching. This single change moves most Grade C pages toward Grade B on the next LLM Scorer run.
Step 4 — Inject Three Sourced Statistics Into the First 500 Words
Scan the first 500 words. Count the sourced, specific statistics with a number, a source, and a link to the primary research.
If the count is below three, add them. Source each one to the primary study, the Gartner report, the Princeton paper, not a blog post that cited it. AI systems follow citation chains. A link to the primary source carries more authority weight than a secondary reference.
Integrate the statistics into the opening section as evidence supporting the answer capsule from Step 2.
Step 5 — Fix the Authorship and Schema Layer
No content changes needed here. This is a technical fix that can move a Grade B page toward Grade A in under two hours.
- Authorship: Replace "Written by the Marketing Team" with a named author linked to a credentials page. Role, years of experience, LinkedIn profile.
- Article schema: Populate the author field, datePublished, and dateModified. Signals active maintenance and real authorship to AI systems.
- FAQ schema: Implement on every Q&A section. Makes the question-answer structure explicitly readable — not just inferred from HTML.
- HowTo schema: Add to any numbered process section. HowTo structured data is directly pulled into AI Overviews in step format.
Validate everything through Google's Rich Results Test before republishing. A schema error means the markup is being ignored entirely.
Step 6 — Update One Statistic and Refresh the Publish Date
Find the most prominent statistic in the article. Check whether a more current version exists from the same primary source. If it does, update it and refresh the source link.
Then update dateModified in the Article schema and the visible "last updated" date on the page.
Five minutes. But it signals to AI engines that the content reflects current knowledge, which matters because pages static for more than six months lose citation frequency on fast-moving topics regardless of how accurate the content remains.
After all six steps, re-run the page through the LLM Scorer and confirm the grade has improved. Most Grade C pages reach Grade B. Many Grade B pages reach Grade A. No existing content deleted. No existing rankings are at risk.
If Your Content Is Not Being Cited by AI, Now You Know Why
Most SaaS content teams will read this guide and recognise their own content library in it. The buried answers. The keyword headings. The anonymous authorship. The pages that rank on Google and generate zero AI citations.
That recognition is the starting point, not the problem.
The problem is continuing to publish more content built on the same structural assumptions while AI engines systematically bypass it. Every month without fixing the architecture is another month your competitors earn the citations that should belong to you.
The good news is that LLM readiness is not a rebuild from scratch. It is a structured fix applied to content you already have. The six dimensions in this guide, extractability, authority, relevance, freshness, access, and repetition, are not new content investments. They are structural decisions that change what AI engines do with the content you have already built.
The buyers in your category are asking ChatGPT, Perplexity, and Google AI Overviews which vendor to shortlist right now. The only question is whether your content is structured to be the answer they get.
If you want an expert to run that audit for you, RevvGrowth's AEO and GEO specialists work exclusively with B2B SaaS companies.
We audit your existing content library, identify your highest-impact citation opportunities, and build the content architecture that gets your brand cited consistently across ChatGPT, Perplexity, Google AI Overviews, Gemini, and DeepSeek, no generic playbooks, no vanity metrics.
.svg)
.webp)